Sommaire [-]
- I. Présentation : Qu’est-ce que Lamp security
- II. Mise en place de notre infrastructure
- III. Étape 1 : La prise d’information
- A. Qu’est-ce qu’un scan ?
- B. Utilisation d’Nmap
- C. Scan de vulnérabilité – Auto
- 1. Nikto
- 2. DirBuster
- IV. Etape 2 : Exploitation
- A. Transversal Directory & Inclusion de fichier
- B. Brute force SSH
- V. Étape 3 : Élévation de privilèges
- A. Vol de la session web
- B. NanoCMS
- C. Identifiants MySQL par la configuration du site web
- VI. Conseil / Correction
I. Présentation : Qu’est-ce que Lamp security
Le projet LampSecurity
est un ensemble de machines virtuelles destinées à l’entrainement, la
compréhension et l’apprentissage de la sécurité de l’information et de
ses systèmes. Il s’agit plus clairement de plusieurs VM volontairement construites avec des vulnérabilités. Le but du « jeu
» étant de les faire démarrer puis de les attaquer. Dans un premier
temps, on apprend comment attaquer pour savoir comment mieux se
défendre. Le SourceForge du projet se trouve sur ce lien : http://sourceforge.net/projects/lampsecurity/files/CaptureTheFlag/
La
sécurité est un élément important dans tout système d'information. Pour
bien sécuriser un environnement, il faut connaitre son fonctionnement,
sa configuration et ses failles. C'est dans ce but que l'ensemble des
machines LampSecurity ont été créées. LampSecurity sont un ensemble de “Capture the flag”
qui ont pour but d'initier ceux qui s'y attaquent aux bases de la
sécurité. Il s'agit de machines contenant le service basique LAMP (Linux – Apache – MySQL – Php)
volontairement vulnérable afin que l'on puisse essayer d'en prendre le
contrôle et ainsi de mieux comprendre certaines attaques et principes de
sécurité.
Bien souvent, le but d'une attaque “réelle”
n'est pas forcément de prendre le contrôle du compte root mais plus de
trouver des informations intéressantes (fichiers, bases de données).
LampSecurity contient bien d'autres failles de sécurité et
apprentissages que ceux qui sont exposés ici. Nous cherchons ici à avoir
le contrôle de root.
Je
vais ici détailler les solutions pour atteindre notre objectif
principal : le contrôle total de la machine par le vol du compte “root”
qui est le super-utilisateur ayant tous les droits sur une machine
Linux.
Note : Il est très important de ne pas lire ce tutoriel si vous n'avez pas tout tenté pour trouver la solution vous-même. Le but principal des machines LampSecurity étant d'apprendre les vulnérabilités d'un système. Il faut bien souvent pour cela passer du temps à ce documenter et ne pas céder à la facilité de trouver des solutions toutes faites sur le net.
II. Mise en place de notre infrastructure
Pour information, j'utiliserais en tant que machine d'attaque la distribution KaliLinux (anciennement Backtrack) qui est une simple distribution Linux contenant un ensemble d'outils souvent utilisés dans le cadre des tests d'intrusion. C’est une distribution qui peut être en LiveCD
(tourné directement depuis une image ISO ou un CD) ou installée sur une
machine. J’ai pour ma part choisi l’installation définitive. Pour
virtualiser mes machines, j’utilise VmWare Workstation 10.
L’infrastructure
sera donc composée de ma machine d’attaque et de la machine cible que
nous déployons sans savoir son IP (elle sera à découvrir  ). Nous allons maintenant voir comment mettre notre machine cible en fonctionnement.
). Nous allons maintenant voir comment mettre notre machine cible en fonctionnement.
Voici le lien pour télécharger la machine vulnérable Lamp Security 5 : http://sourceforge.net/projects/lampsecurity/files/CaptureTheFlag/CTF5/Il faut donc télécharger le ZIP et le décompresser sur votre poste. Il s'agit d'une machine virtuelle qui ne peut tourner que sous VmWare Workstation ou Player (ce dernier étant gratuit et téléchargeable). Ayant fait le pentest une fois avant de faire le tutoriel, mes explications vont droit au but et n’exposent pas les recherches et tests infructueux. C’est pour cela que je vous conseille, si vous êtes réellement bloqué, de suivre une étape pour vous débloquer mais d’essayer de vous débrouiller pour la suite. Lire le tutoriel sans fouiller et chercher n’ayant aucun intérêt.
On se retrouve donc avec notre CTF5.zip qu’il faut décompresser pour avoir ce dossier :
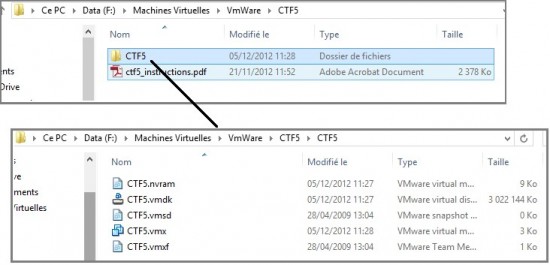
Dans le dossier « CTF5/CTF5
» on se retrouve avec les différents fichiers composants une machine
virtuelle VmWare. Il nous suffit de cliquer sur le fichier « CTF5.vmx » pour lancer la machine virtuelle :
Note : Cette vue est spécifique à VmWare Workstation, elle peut différer sous VmWare Player mais la configuration de la machine cible sera la même.
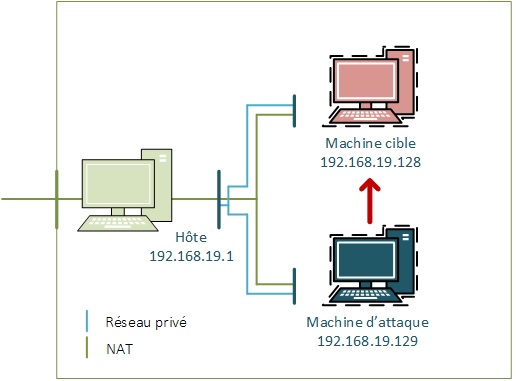
Une petite
précision sur la configuration réseau de la machine. Étant donné que
nous n’avons pas accès à sa configuration, il nous faut au moins savoir
sur quel réseau elle se trouve. On remarque pour cela que la carte
réseau « Network Adaptater » est sur le NAT. Sous VmWare, la carte NAT
permet au poste virtuel d’aller sur le réseau « en tant que » la
machine hôte (avec la même IP) mais permet également à toutes les
machines et à l'hôte de ces machines de communiquer dans un réseau qui
leur est privé.
Les machines sous NAT partagent une plage IP de la carte réseau virtuelle de l’hôte qui se nomme « VMnet8
». On peut voir cette configuration de plage IP lorsque l’on ouvre une
invite de commande (sous Windows) et que l’on saisit la commande « ipconfig » :

On voit donc que les machines virtuelles dans le réseau NAT seront dans la plage IP 192.168.19.0/24. On prendra donc soin de mettre la carte réseau de notre machine virtuelle d’attaque cible également en NAT.
On allume donc nos deux machines virtuelles pour débuter notre entrainement .
III. Étape 1 : La prise d’information
Nous
allons commencer par essayer d’avoir un peu plus d’information sur
notre cible afin de savoir à qui nous avons à faire. Généralement, la
prise d'information (Information Gathering) se fait d'abord en “mode”
passif. Dans une attaque réelle, on essaierai de voir ce qui traine
comme information sans essayer d’interagir avec elle ou de communiquer
avec elle. On regardera par exemple les informations des DNS mondiaux
pour avoir des informations sur sa location, ses propriétaires, etc ..
C'est une partie sur laquelle je suis loin d'être expert et que je ne
développerais donc pas ici. Dans un deuxième temps, on procède à une
prise d'information “active” ou cette fois-ci nous allons chercher à
“faire dire” à notre cible des informations à propos d'elle pour pouvoir
exploiter ces informations.
On va pour cela utiliser le logiciel Nmap (Network Mapper, www.nmap.org). Nmap
est utilisé pour la découverte de réseau. On l’utilise en général pour
scanner des plages d’adresse IP afin de détecter quelles IP sont
utilisées (celles qui répondent). On utilise également Nmap pour faire du scan de port.
A. Qu’est-ce qu’un scan ?
L’action de Nmap
est donc de solliciter un nombre d’IP ou de port par IP afin de voir si
un service ou une IP est active et ainsi nous donner des informations
sur les services ou l’activité d’un hôte. Si le port ou l’IP sollicité
répond, alors c’est qu’il y a une activité et Nmap
cherchera, si on lui demande, d’avoir plus d’information sur l’hôte ou
le port comme par exemple l’application qui la fait tourner, sa version,
etc.
NMap peut
aller jusqu’à découvrir sur quel OS tourne l’hôte que nous interrogeons
et ainsi cibler nos attaques vers cet hôte. Il est généralement inutil
d’attaquer à l’aveugle un hôte sans avoir un minimum d’information à son
sujet. C’est pour cela que la première partie de l’attaque est la
récupération d’un maximum d’information. Les informations comme l’IP,
les services et ports ouverts, les versions des applications nous
permettront d’orienter nos attaques et de restreindre leur nombre afin
d’être plus discret et plus efficace. Ceci est juste à titre informatif,
étant donné qu'il s'agit ici d'une plateforme d'entrainement, la
discrétion n'est pas notre but.
B. Utilisation d’Nmap
Nmap peut être utilisé en ligne de commande ou en interface graphique. La distribution Kalilinux embarque nativement une version en ligne de commande. C’est parti !
On va donc chercher dans un premier temps à repérer l’IP de notre cible :
Détaillons un peu cette commande :
- ”sn” permet de ne pas scanner les ports par hôte. Par défaut, dès qu’nmap trouve une IP, il va automatiquement chercher les ports actifs. C’est une perte de temps lorsque l’on cherche seulement des IP ou un hôte spécifique, il est inutile de savoir quel port y est ouvert ou non.
- “192.168.19.1-255” : on spécifie ici une plage d’IP, c’est-à-dire un ensemble d’IP que nmap va passer en revu une par une.
On arrive donc avec un résultat comme celui-ci (qui peut varier selon la plage d’IP sur laquelle se situent vos machines !) :
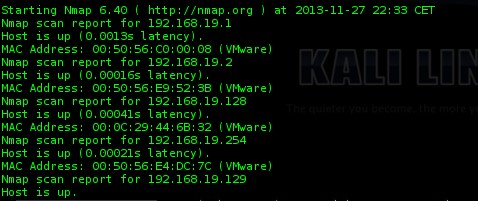
On
voit donc différentes adresses IP qui ont répondues présentes à notre
scan ! Je sais ici que ma machine d’attaque possède l’IP 192.168.19.129. On remarque l’IP 192.168.19.128. Sachant que j’ai démarré mes machines environs au même moment. Il est probable que .128 soit l’IP de ma machine cible.
Note : Cette réflexion n’est pas forcément applicable dans un cas réel mais permet de se familiariser avec l’utilisation et les résultats d’nmap.
On présume donc que l'IP de notre cible est “192.168.19.128“.
Maintenant que nous avons l’IP de notre cible, il nous faut savoir
quels sont les services qui tournent sur cette machines. On utilise à
nouveau nmap :
Détail de la commande :
- “192.168.19.128” : on spécifie l’IP de notre cible au lieu de spécifier une plage d’IP (un ensemble d’IP)
- “-p1-65535” : Par défaut, Nmap ne scan pas tous les ports, nous cherchons donc ici à annoncé à nmap tous les ports qu'il va devoir contacter
- A” : permet d’effectuer un scan dit « agressif » qui, entre autre, permet de tenter une détection de l’OS de l’hôte, la version des applications faisant tourner les services détectés…
- ”-V” : permet d’augmenter la verbosité de la commande (les résultats qu’elle affichera sur le terminal)
En somme, nous souhaitons maintenant avoir un maximum d’information sur notre cible. Une fois lancé, nmap
va scanner plus de 60 000 ports. Il se peut que le résultat mette un
peu de temps à venir. Pour gagner du temps, on peut restreindre notre
scan sur les « well known port » qui sont les 1024 premiers ports, la commande deviendra alors :
Il est important de noter que ce type de découverte est très peu discrète. Des systèmes IDS
(détecteurs d’intrusion) peuvent facilement détecter le fait qu’une
machine essai un nombre très important de port ou d’IP sur un système ou
un réseau. Le résultat nous affichera beaucoup d’information que nous
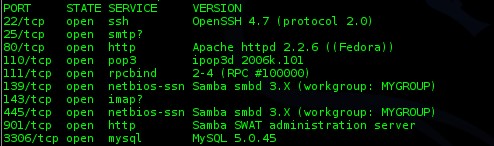
allons essayer de démêler. On retrouvera parmi les choses intéressantes :
Début du scan :
Résultat sur le port SSH. Nous avons ici un exemple parlant. Le scan de port Nmap sur notre hôte a eu une réponse sur le port 22, il a donc cherché à avoir des informations sur l’application qui faisait tourner ce service :
On voit donc que le port SSH a répondu en TCP et que nmap a découvert que c’est l’application OpenSSH version 4.7
qui faisait tourner le service SSH en utilisant la version 2 du
protocole (ce qui est aujourd’hui toujours le cas car la version 1 du
protocole SSH présentait de faille de sécurité). Nmap a
également récupéré les clés publiques DSA et RSA du serveur. C’est ce
que nous récupérons lorsque nous établissons une connexion SSH avec le
serveur. Cela ne présente que peu d’intérêt ici mise à part peut être le
fait de connaitre leur taille.
On voit également qu’il a obtenu une réponse sur le port 25 qui est le port standard SMTP
(envoi de mail), cependant, il n’a pas réussi à détecter l’application
faisant tourner ce service et n’a pas réussi à établir de connexion sur
ce port :
D’autres
informations intéressantes sont récupérées sur le port 80 qui est le
port par défaut web. On voit que la version du serveur web utilisé est Apache 2.2.6 le fait qu’il y soit indiqué “httpd” indique également que c’est une Fedora, Centos ou dérivée car sur ces distributions, le service Apache est nommé « httpd » :
On voit également des informations sur les méthodes utilisées lors des échanges ainsi que le titre http qui semble être « Phake Organization »
Détection d’un port 110 ouvert, il s’agit généralement du port pour le pop3 :
Port netbios Samba, on peut imaginer que des partages vers l’extérieur sont configurés :
Détection d’un port 143 ouvert, il s’agit généralement du port pour l’imap. On note toutefois qu’aucune connexion n’a réussi :
Le port d’administration et d’accès MySQL semble également ouvert :
Une fois la détection des ports faite, on peut avoir plus d’information sur l’OS de notre cible :
L’option “-A”
d’nmap effectue automatiquement un traceroute qui permet de savoir par
quelle machine nous passons (pare-feu par exemple) pour communiquer avec
notre machine. On voit par exemple ici que notre machine est sur le
même réseau que nous et qu’il ne semble pas avoir de passerelle entre la
machine d’attaque et cible. On peut donc supposer (supposer seulement
!) que la sécurité sera moindre que s’il y avait un pare-feu entre les
deux qui aurait peut-être été capable de filtrer nos requêtes. Il peut
toutefois toujours avoir un pare-feu interne à la machine ou un système
de détection d’intrusion :
Pour avoir une vue un peu plus brève, on peut utiliser la commande suivante :
- “O” : Permet de forcer la détection de l’OS
- “Pn” : Permet de considérer l’hôte comme actif (pour passer la phase de détection de l’hôte d’nmap)
- “sV” : Joue avec les ports pour déterminer les informations sur les services en question
Ces
informations peuvent servir de point de départ pour détecter des
éléments non mis à jours comportant des failles de sécurité connues
(expoit-db/ metasploit). Maintenant que nous avons d’avantage
d’information sur notre hôte et les services qu’il fait tourner. Nous
pouvons nous attarder sur les vulnérabilités et les failles que ces
différents services pourraient comporter. Il y a ici plusieurs « angles
d’attaques », on peut se renseigner sur les éventuelles failles de
sécurité connue que certaines versions (trop veilles) d’applications
pourraient comporter sur des sites comme www.exploit-db.com, utiliser des outils de scan automatisés comme Nessus, Metasploit ou Nikto
(pour le web par exemple), ou aller fouiller à la main les services en
questions (ce qui est souvent plus laborieux mais plus précis qu’un scan
« générique »).
C. Scan de vulnérabilité – Auto
1. Nikto
Étant
donné que nous sommes sur un exercice de sécurité axé sur le web
(système LAMP), nous allons en profiter pour nous initialiser à Nikto
qui est un outil de scan de vulnérabilité web complet et plutôt simple
d’utilisation. Nikto est intégré dans les solutions KaliLinux et
Backtrack :
Qu'est ce que Nikto ?
Nikto
est un produit Open Source (Licence GPL) qui est un scanneur de
vulnérabilité web écrit en perl, il permet de scanner de façon simple et
rapide un serveur web afin d’y détecter d’éventuelles failles de
sécurité. L’action de Nikto est donc d’effectuer divers tests sur une
cible donnée (un serveur web, son ou ses ports ou une URL particulière).
Il permet de détecter des versions obsolètes de services web, des
failles CGI / XSS, il peut également rechercher des dossiers contenant
des informations sensibles.
Nous aurons alors beaucoup d’information sur les découvertes faites par Nikto. On remarquera quelques évènements important :
- La détection des versions de serveur web et PHP utilisées. On pourra alors voir si ces versions comportent des failles de sécurité si ce ne sont pas les dernières :
On voit également certains dossiers d'application spécifiques qui peuvent être des points d'entrés supplémentaires :
2. DirBuster
Un autre scanneur web souvent utilisé est DirBuster (https://www.owasp.org/index.php/Category:OWASP_DirBuster_Project ), il est également intégré dans les solutions KaliLinux ou Backtrack. Celui-ci se gère en interface graphique. On le lancera donc de la façon suivante :
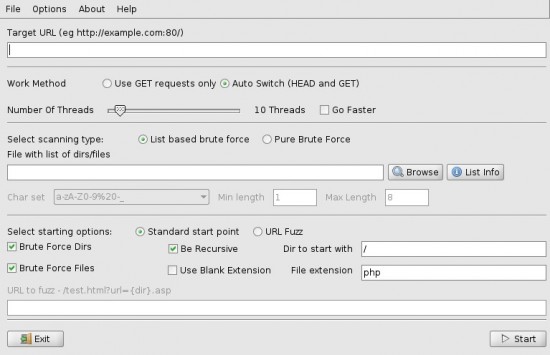
Qu'est ce que DirBuster ?
DirBuster est donc une application qui va « brute-forcer
» les répertoires et les noms de fichiers d’un site ou d’une
application web d’un serveur afin de chercher des réponses et ainsi en
savoir plus sur ce qui est hébergé sur le serveur en question.
Qu'est ce que le “brute-force” ?
Le fait de brute-forcer signifie que DirBuster
va tenter plusieurs centaines voir milliers de combinaisons de
caractère afin de chercher une correspondance. C’est une technique très
peu discrète car chaque tentative, fructueuse ou non, est affichée dans
les logs. Si une seule IP apparait plusieurs milliers de fois en très peu de temps dans un fichier de logs, cela est vite suspicieux.
On
voit donc que l’on peut spécifier bon nombre d’option afin de calibrer
notre scan. La première chose à saisir est l’URL du serveur à scanner.
On saisit donc l’IP du serveur :
DirBuster
va donc partir de la racine de notre serveur web et faire une recherche
par brute force à partir de cette racine. Si nous souhaitions scanner
une URL ou une application particulière, nous aurions aussi pu spécifier
l’URL comme ceci
On peut également spécifier le nombre de Threads (processus) qui seront assignés à la tâche du brute force. Selon le dictionnaire que l’on prend, cela peut être assez long.
Brute force et dictionnaire ?
Le
fonctionnement du brute-force par dictionnaire est assez simple à
comprendre. Un dictionnaire est un ensemble de mots ou caractères
disposés par ligne, chaque mot sera un test effectué vers le serveur
pour voir si une réponse est faite. Le but d’un dictionnaire est de
calibrer l’attaque sur des mots connus comme « phpmyadmin » ou « index.php
» au lieu de tester des caractères aléatoires un par un. Dans le cadre
d’une recherche sur un serveur web, il est plus courant de trouver plus
ou moins les mêmes titres de dossiers/page comme « admin », « icons » ou « login.php ». La recherche par dictionnaire est donc la plus intéressante.
C’est pour ça que nous avons le choix entre « List based brute force » qui équivaut à l’attaque par dictionnaire et « Pure brute force
». Nous allons choisir la première option mais il nous faut pour cela
un dictionnaire. Il en existe des tout fait sur le net qui contiennent
les dossiers et nom de fichiers les plus couramment utilisés. On peut
par exemple se rendre sur l’URL suivante : http://sourceforge.net/projects/dirbuster/files/DirBuster%20Lists/Current/
On peut les télécharger simplement en ligne de commande avec la commande suivante :
On va ensuite décompresser l’archive :
Puis retourner dans la fenêtre de paramétrage de DirBuster, cliquer sur « Browse » et aller chercher un des fichiers dictionnaires, prenons par exemple « DirBuster-Lists/direcroty-list-2.3-medium.txt». Si vous ouvrez un des fichiers situés dans le dossier « DirBusterList », vous remarquerez qu’il y a bien un nom de dossier ou fichier par ligne :
On pourra ensuite cliquer sur « Start » pour lancer le scan. On ira alors dans l’onglet « Tree View » pour voir les résultats s’afficher progressivement. S’afficheront ici seulement les répertoires et fichiers que DirBuster à réussir à détecter sur le serveur. DirBuster est donc pendant le scan en train de lire ces lignes une par une et de tester un accès sur la cible donnée :
C’est comme cela que le brute force par dictionnaire fonctionne. Un brute force « pure » aurais testé un ensemble de caractère avant de passer aux suivants :
Et
ainsi de suite, ce qui est beaucoup plus long car un nombre très
important de ces possibilités sont très improbables. En revanche, si on
laisse tourner le scan longtemps (très très longtemps), nous aurons plus
de chance de trouver les dossiers présents sur le serveur web. La
deuxième solution étant extrêmement longue, elle est rarement utilisable
en situation réelle. Il faut souligner que ces deux méthodes sont très
peu discrètes aux yeux des administrateurs du serveur cible. Si l’on
regarde en bas de notre fenêtre, nous verrons d’ailleurs le nombre de
requête total effectuée et à faire ainsi que des estimations de temps
pour finir la tâche :
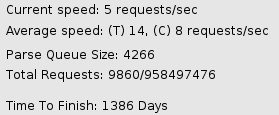
Mon « Time to Finish
» est extrêmement long, cela dépendra de la puissance de votre machine,
du temps de réponse du serveur et du débit de la connexion qu’il y a
entre les deux. Pour ma part, j’arrête le brute force à 10 000 requêtes
mais cela signifie que toutes les possibilités n’ont pas été tenté et
que je passe peut être à côté de certaines informations !
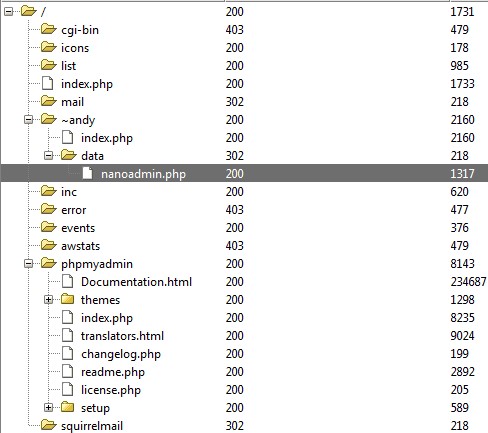
Revenons un peu à notre résultat. Remarquez tout de même que nous avons déjà des informations intéressantes avec Nitko et DirBuster sans même se rendre sur le serveur web via un navigateur. On voit un dossier « ~andy » qui contient un dossier « data » puis « nanoadmin.php », les pages admin.php donnent souvent des accès d’administration sur des applications web. Je pense par exemple au dossier « wp-admin/ » sous WordPress.
Essayer de prendre le contrôle de ces pages pourra peut-être nous
permettre d’avoir plus de privilège sur notre cible. On trouve également
une liste de répertoire à visiter ainsi que d’application à vérifier (awstats, squirrelmail (1.4.11)) pouvant être exploités.
IV. Etape 2 : Exploitation
Maintenant
que nous avons récupérer un bon nombre d’information sur notre serveur
grâce à des outils de scan, nous allons pouvoir passer à la phase
suivante qui est la découverte manuelle et l’exploitation de ces
failles. Nous allons donc utiliser les informations collectées
précédemment pour tenter des entrées sur le serveur cible. Le but étant
de vérifier les informations fournies par les outils pour voir si elles
nous donnent accès à des informations intéressantes.
A. Transversal Directory & Inclusion de fichier
L’analyse Nikto nous a révélé qu’il y avait la possibilité d’inclure un fichier du système lisible par tous depuis une page web grâce à la requête faite en interne sur les pages : « /index.php?page= ».Qu'est ce que le transversal Directory ?
Le transveral directory est le fait qu'un attaquant parcours l'arborescence du serveur via une application ou un site web par exemple. Cela ce produit généralement quand le serveur ne contrôle pas les requête envoyée par les clients.
Qu'est ce que l'inclusion de fichier ?
L'inclusion de fichier est le fait de faire lire au serveur des fichiers et de profiter de ses droits pour cela. On voit ici dans notre requête qu'index.php attends un nom de fichier pour la variable “page”. Cela peut nous indiquer que la page utilise la fonction “include” PHP qui permet d'inclure dans la page en cours un autre fichier PHP. Si au lieu d'envoyer une demande pour la lecture d'un page PHP, nous envoyons une demande pour lire le fichier “/etc/passwd” du serveur, nous faisons une attaque par inclusion de fichier.
Nous allons donc essayer de charger le fichier « /etc/passwd » qui est automatiquement lisible par tous avec la requête suivante :
On remarque alors le message d’erreur suivant :
On voit plus clairement que le système essai de charger le fichier “passwd.php“, cela vient du fait que le système ajoute un “.php” lors de l’utilisation d’un include. Nous allons donc mettre fin au nom du fichier avec un caractère ASCII HTML représentant un vide/espace « », la requête devient alors :
et nous aurons la réponse suivante :

Nous affichons donc le contenu du fichier « /etc/passwd » avec le nom des utilisateurs.
En quoi cela peut-il nous être utile ?
Le fichier “/etc/passwd”
est le fichier contenant le nom de login de tous les utilisateurs du
système. On voit aussi dans ce fichier lesquels on un droit d’accès en
shell sur le serveur. Les utilisateurs ayant un accès shell deviennent
donc des cibles pour un brute force SSH. Un brute force sur deux champs
inconnus (login + mot de passe) est très très fastidieux. Pour qu’un
brute force soit plus intéressant a faire, il nous faut ou moins l’un
des deux champs, c’est ce que nous obtenons ici. On notera donc les nous
d’utilisateurs suivants :
- Amy
- Loren
- Andy
- Jennifer
- Patrick
On remarque aux passages des utilisateurs d’applications :
- Bureau Gnome : gdm
- Openpn : openvpn
- MySQL : mysql
- Cyrus IMAP serveur :cyrus
Ce
qui peut être une base pour une tentative de brute force SSH. Dans le
code source de la page, le fichier s’affichera avec un
utilisateur/ligne. On peut alors identifier les utilisateurs mais aussi
les services installé plus facilement. Pour afficher le code source, il
suffit de se rendre sur la page et de faire un clic droit « Afficher le code source » :
 Nous aurons alors cet affichage :
Nous aurons alors cet affichage :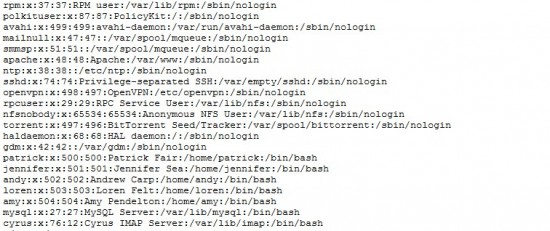
B. Brute force SSH
Maintenant
que nous avons récupéré les utilisateurs, nous pouvons tenter un brute
force sur certains comptes. Nous allons pour cela utiliser le logiciel «
hydra » qui permet de faire des brutes force SSH. Il est déjà installé sur KaliLinux. De la même manière, nous pouvons tester un brute force « pure
» ou un brute force par mot de passe, nous utiliserons ici la méthode
par dictionnaire qui est souvent moins longue. On va pour cela aller
télécharger un dictionnaire de mot de passe qui contient généralement
les mots de passe les plus couramment utilisés (Ex : « soleil », « 123456 », « password
»). L’utilisation de mots de passe faibles de ce genre est beaucoup
plus fréquente qu’on ne l’imagine. Pour ma part, je télécharge la liste
de mot de passe sur ce lien : http://wiki.skullsecurity.org/Passwords
Je prends ici le fichier « john.txt.bz2 » que je décompresse avec la commande suivante :
Étant
donné que nous avons également une liste d’utilisateur à tester (les
logins), nous devons créer un fichier texte contenant ces noms :
Un login par ligne :
Par curiosité, nous pouvons calculer combien de possibilité cela fait. On voit avec la commande « cat john.txt |wc –l » que le fichier de mot de passe « john.txt » contient 3107 mots de passe (on compte les lignes avec « wc –l » car il y a un mot de passe par ligne). On fait donc 5 utilisateurs * 3107 mots de passe ce qui nous donne 15535 tests à effectuer. Je vous laisse imaginer la tête qu’aurons les logs
d’authentification du serveur cible à la fin de ce test. Tout cela pour
vous resouligner que le brute force n’est absolument pas discret.
Nous utilisons donc hydra de la manière suivante :
Nous utilisons donc hydra de la manière suivante :
- “-L” : On précise le fichier contenant la liste des utilisateurs
- “-P” on précise le fichier contenant la liste des mots de passe
- On précise ensuite l’IP cible puis le protocole utilisé (ici SSH).
Selon
la puissance de votre machine d’attaque et cible, on peut également
augmenter le nombre de tâches qui seront affectés à ce brute force avec
l’option –t (5 par défaut) Il ne nous reste donc plus qu’a attendre pour
voir si hydra trouve des correspondances correctes.
Au bout de 30 minutes de brute force :
Au bout de 30 minutes de brute force :
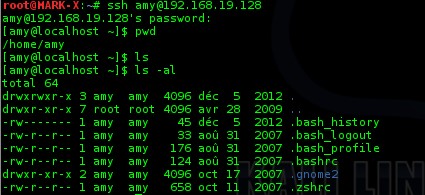
Hydra
a donc trouvé une correspondance entre le login amy et le mot de passe
dolphins. On peut donc tenter une connexion SSH avec ces identifiants
On aura accès à la session et au compte d’amy sur le serveur. Les plus curieux prendront le temps de visiter le serveur pour voir les informations qu’ils peuvent en tirer.
V. Étape 3 : Élévation de privilèges
Maintenant
que nous avons un accès sur le serveur, il faut récupérer encore plus
d’information pour élever nos privilèges qui, au premier abord, sont
ceux d’un simple utilisateur. Fouillons un peu ce serveur. En allant
dans le dossier “/home”, on remarque que tous les “/home” des autres utilisateurs sont lisibles :
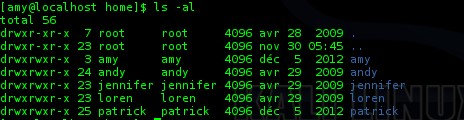
Par défaut sous Linux, les dossiers “home” créés pour les utilisateurs sont “World Readable”
ce qui signifie que tout le monde peut les lire. C'est un problème de
sécurité comme nous allons le voir car cela permet aux utilisateurs de
lire les fichiers des autres utilisateurs. C'est un problème que nous
avons déjà abordé dans ce tutoriel : L’umask sous Linux
On
peut donc aller fouiller les sessions des autres utilisateurs. Toutes
les applications, noms de fichiers auxquels nous pouvons accéder sont
susceptibles de nous donner des informations, il faut donc se renseigner
sur chaque application que nous ne connaissons pas pour être sûr de ne
rien louper. Je prends par exemple les fichiers cachés .bash_history
qui peuvent contenir des commandes et informations précédentes sur ce
que l’utilisateur a pu saisir lors de ses précédentes sessions ou le
fichier .mysql_history qui peut contenir des informations sur les bases de données MySQL.
A. Vol de la session web
- On peut tester la commande « mail » qui permet d’afficher ses mails en lignes de commande sous Linux. On voit alors que notre utilisateur amy a des mails :
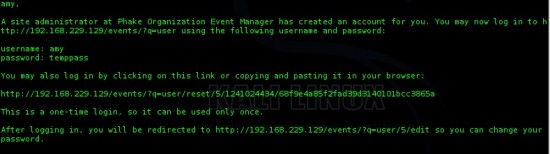
Intéressant,
il semblerait que ce mail soit une réponse à une demande de
réinitialisation de mot de passe. Voyons ce que l’on peut faire en nous
rendant directement sur le site web et en demandant une réinitialisation
du mot de passe d’amy. Une fois sur la page d’accueil, il faut trouver
un endroit où s’authentifier. On voit qu’il y a une fenêtre
d’authentification dans la partie “Events” avec un “Request new password” :
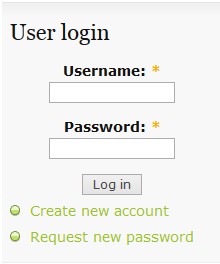
Il n’y a plus qu’à cliquer ! On nous demande alors soit un mail, soit un nom d’utilisateur :
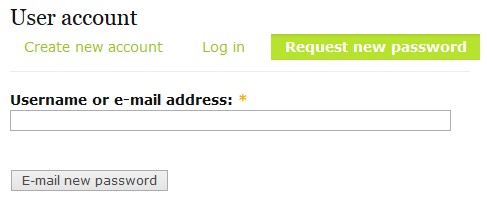
On connait le nom d’utilisateur « amy ». On le saisit puis on clique sur « E-mail new password
». On recevra alors un mail de réinitialisation de mot de passe sur le
compte d’amy que nous pourrons voir avec la commande « mail » :
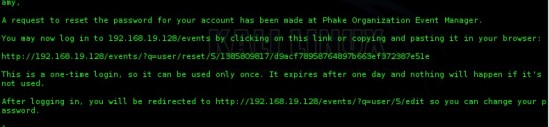
On peut alors se rendre sur l’URL indiquée :
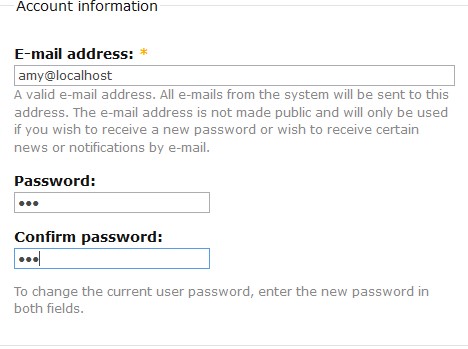
On clique sur “Login” puis nous pourrons changer le mot de passe de l’utilisateur.
On clique sur “Submit”
en bas de page et nous avons ensuite accès au site web en mode
authentifié. A ce moment-là, l’utilisateur n’aura plus accès à son
compte et alertera son administrateur système.
B. NanoCMS
- Dans le “/home/andy” on remarque un dossier dont le nom peut faire penser à un dossier web “public_html “. On peut croiser cette information avec l’analyse DirBuster faite précédemment ou nous avions un dossier “~andy” ainsi qu’une page “nanoadmin.php” . “nanoadmin” n’est pas un nom de page courant. On peut faire une recherche sur internet pour voir si cela fait partie d’une application connue : http://lmgtfy.com/?q=nanoadmin+php+web
En cherchant un peu, on verra que le CMS nanoCMS sotcke des mots de passe dans le fichier “/data/pagedata.txt” (http://www.madirish.net/304). On peut donc s’y rendre :

Le
fichier peut paraitre illisible vue comme cela. Mais si on prend le
temps de regarder, nous verrons des informations intéressantes :
- Username : admin
- Password : ce qui ressemble à un hash md5
Qu’est ce que le MD5 ?
un MD5
(Messag Digest 5) est une fonction de hashage connu est souvent utilisé
mais qui n'est plus considéré comme fiable à l'heure actuelle
Qu’est ce qu’un hash ?
Un
hash est une empreinte d'un mot ou d'un ensemble de caractère. Il est
différent d'un chiffrement qui, par rapport au hash, peut être déchiffré
et retrouvé à partir du message chiffré.
Nous venons de voir ce qu’est un hash. Il faut savoir qu’il existe des rainbow table qui peuvent nous permettre, en ne disposant que du hash, de retrouver le message d’origine : http://www.md5decrypter.co.uk/
Il nous suffit alors de recopier le hash obtenu un peu plus haut pour voir si il est présent dans la rainbow table de ce site :
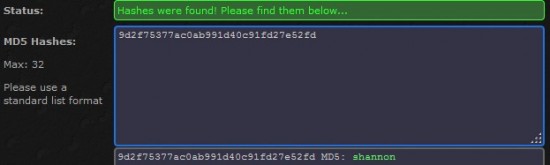
Il semblerait donc que le mot de passe de l’administrateur du site soit « shannon ». Mais ce login/mot de passe ne fonctionne pas dans la partie « events ». Si l’on fouille un peu plus le site, on voit dans la partie « blog » une autre demande d’authentification. On peut essayer ici :
Et ça marche ! On a maintenant accès au blog sous nanoCMS en administrateur
C. Identifiants MySQL par la configuration du site web
Au delà des sessions des autres utilisateurs, on remarque que l’on a également accès au dossier /var/www. Dans le dossier « html » se trouve différents dossiers dont celui du site « events
» sur lesquels nous étions tout à l’heure. Étant donné que le site
utilise des login/mots de passe, il est possible que celui-ci utilise
une base de données MySQL auquel cas il doit avoir un fichier de configuration spécifiant sous quel login le site doit interagir avec le serveur MySQL. Une petite recherche du mot « mysql » dans tous les fichiers du dossier nous éclairera surement :
- “r“: récursivité
- “i” : insensibilité à la casse
- “l” : n’affiche pas les lignes mais juste les fichiers où a été trouvé le mot recherché
Nous avons beaucoup de retour :
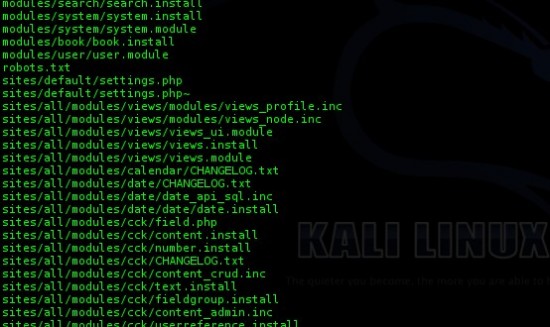
Mais parmi tout cela, on remarque le « site/default/settings.php » où l’on peut se rendre :
En parcourant le fichier, on voit cette ligne :
On repère ici la trame :<user>:<password@cible qui nous indique :
- User : root
- Mot de passe : mysqlpassword
On peut donc directement tester cet accès en ligne de commande :
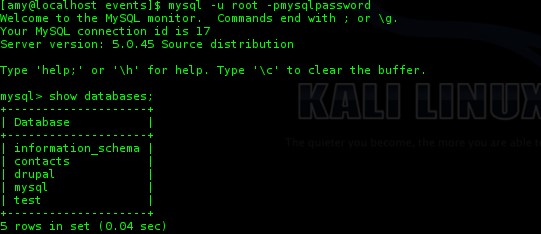
Nous
avons maintenant accès à l’intégralité des bases de données du serveur
cible. On peut directement aller voir si d’autres utilisateurs sont
enregistrés dans la base d’utilisateur MySQL :
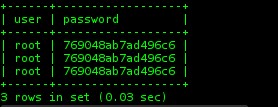
On remarque qu’il n’y a que “root” d’enregistré. Étant donné que nous nous sommes identifié avec « amy » sur le site précédemment. On peut imaginer que les utilisateurs sont dans une autre base mysql. On fouille un peu les différentes tables pour tomber sur drupal.users :
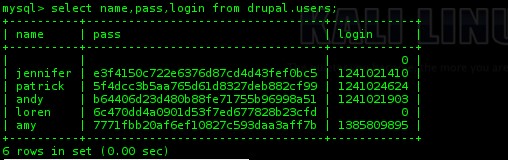
Nous avons à nouveau des mots de passe qui semblent être hashé en MD5. On reproduit la manipulation de tout à l’heure pour retrouver le message original d’un hash avec une rainbow table pour avoir ce résultat :
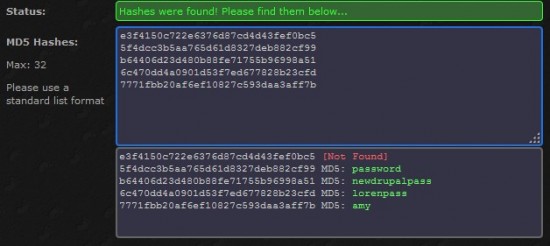
Pourquoi Not Found ?
Ce genre d'outils fonctionnent avec des rainbow table,
cela permet de retrouver des mots de passe “faibles” ou souvent
utilisés. Si l'outil n'a pas réussi à retrouver le mot de passe à partir
de sa rainbow table, il est possible que ce soit parce qu'il s'agit d'un mot de passe fort.
Qu’est ce qu'une rainbow table ?
Une rainbow table
est une simple base de données avec une correspondance mot –> Hash.
Il s'agit en gros d'une base de données regroupant tous les hash
des mots de passe connus/ faibles. Cela permet, en faisant une
recherche sur le hash, de retrouver le mot de passe duquel il provient.
- En tant qu’amy, on peut enfin se rendre sur la session de patrick qui semble un peu plus remplie que les autres :
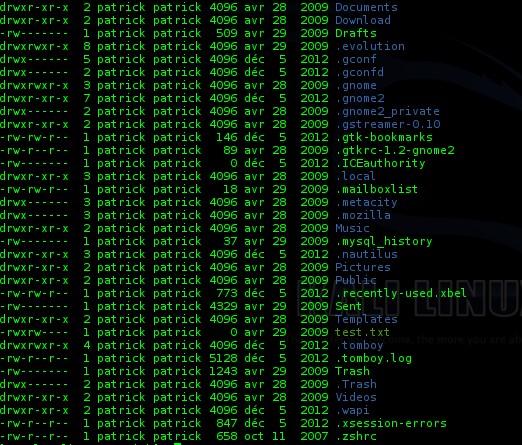
On remarque, entre autres, un dossier « tomboy ». En se renseignant un peu (http://lmgtfy.com/?q=linux+tomboy ) On voit que tomboy est une petite application de prise de note. Voyons ce que patrick a pu nous noter d’intéressant sur son bureau :
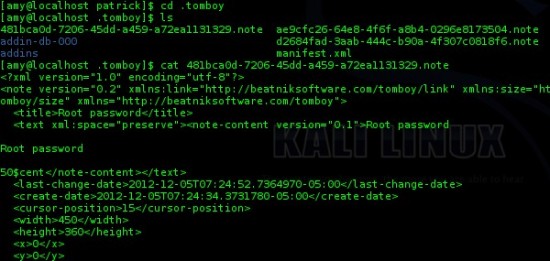
Bingo ! Patrick a simplement noté le mot de passe « root » sur son bureau via tomboy : 50$cent
On test l’accès :

Nous avons maintenant un contrôle total du serveur. Mission accomplie !
VI. Conseil / Correction
Quels sont les problèmes majeurs du serveur qui nous ont permis d’accéder au contrôle du serveur :
- Cacher les versions
Il
est très important de systématiquement cacher les versions d'OS,
d'application et de services utilisés. Il s'agit de l'une des premières
informations que les attaquants vont chercher à avoir pour cibler leur
attaques. Moins ils auront d'information, plus leur attaques seront
hasardeuses, peu discrètes et longues. Le principe principal de la
défense d'un systèmes d'information n'est pas de rendre la pénétration
et le piratage impossible mais de les rallonger au maximum pour
décourager l'attaquant et le repérer plus facilement.
- Changer les ports dans la mesure du possible
Les
“well known port” sont les ports dédiés à une application bien connue
et bien déterminée. Le plus souvent, un attaquant ne cherchera même pas à
savoir sur quel port il peut lancer son brute force SSH car il s'agit
du port 22. Si on change le port d'accès SSH en 55002 par exemple,
l'attaquant mettra plus de temps à le trouver (si il le trouve). Cela
s'applique non seulement au SSH mais également a bien d'autres services.
- Gestion de l'umask et des droits Linux
La
gestion et l'attribution par défaut des droits sur les dossiers et
fichiers sous Linux n'est pas optimale d'un point de vue de la sécurité.
On a vu que par défaut, un utilisateur pouvait accéder à certains
dossiers/fichiers des autres utilisateurs, pouvant ainsi récupérer des
informations. Si une session est compromise sur le serveur, cela peut
rapidement devenir problématique. Un tutoriel sur la gestion de l'umask
est indiqué à l'endroit de l'exploitation de cette faille de sécurité.
- Gestion des mots de passe
La
gestion des mots de passe utilisateur n'est pas simple à mettre en
place car, la plupart du temps, nous ne sommes pas à même de les
vérifier. Il existe néanmoins des méthodes de vérifications de création
de mot de passe qui permettent de s'assurer qu'un mot de passe fort à
été utilisé. Les mots de passe faibles son extrêmement vulnérables aux
attaques par brute force et mettent ainsi en danger la fiabilité d'une
session, d'un compte et d'une machine toute entièr.
- Ne jamais noter les mots de passe
- Utiliser des fonctions de hash/chiffrement fort
Aucun commentaire :
Enregistrer un commentaire